More about built-ins
Are you familiar with Python's built-ins?
Iterator wrappers
기본 제공되는 유용한 iterator wrapper는 enumerate와 zip이 있습니다. 각각 iteration 과정에서 index가 value와 함께 필요한 경우,
# Don't:
for i in range(len(a)):
foo(i, a[i])
# Do:
for i, v in enumerate(a):
foo(i, v)
그리고 여러 개의 iterable을 동시에 iteration하는 경우에 사용합니다.
# Don't:
for i in range(len(a)):
foo(a[i], b[i])
# Do:
for v, w in zip(a, b):
foo(v, w)
둘 모두 하지 말라고 하는 공통적인 이유는 속도 차이가 상당히 많이 나기 때문입니다. 이에 대한 좀 더 자세한 논의는 바로 뒤에 이어서 다룹니다.
그러나 zip을 사용해야만 하는 더 큰 이유는 두 iterable의 길이가 다른 경우 indexing을 하면 예기치 못한 IndexError가 발생할 수 있지만, zip은 둘 중 더 길이가 짧은 iterable의 길이까지만 사용하기 때문입니다. 속도 차이야 무시하고 쓰더라도, 에러가 발생하는 것은 최대한 방지해야 하겠죠.
a = [1, 2, 3]
b = [4, 5]
# IndexError
for i in range(len(a)):
foo(a[i], b[i])
# Supplies (1, 4) then (2, 5) (no IndexError)
for v, w in zip(a, b):
foo(v, w)
Benchmarks
Python은 indexing시 메모리에 직접 접근하여 비용이 거의 들지 않는 C 등의 언어와는 달리, indexing도 일종의 함수 호출 과정을 거치므로 상당한 비용을 지불합니다. 따라서 indexing의 속도가 매우 느립니다. 앞서 사용했던 코드의 시간을 실제로 측정해 보면 다음과 같습니다.
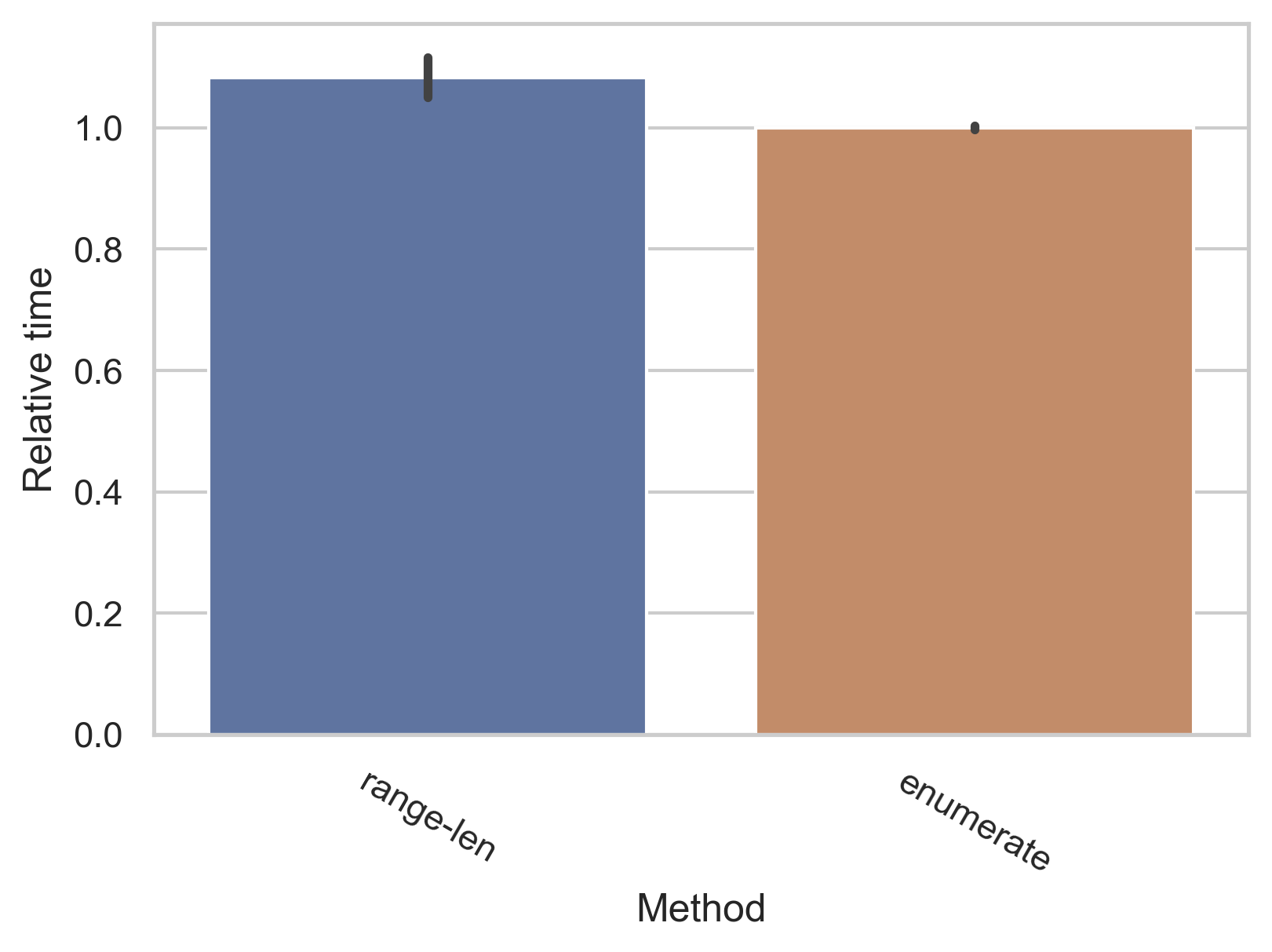
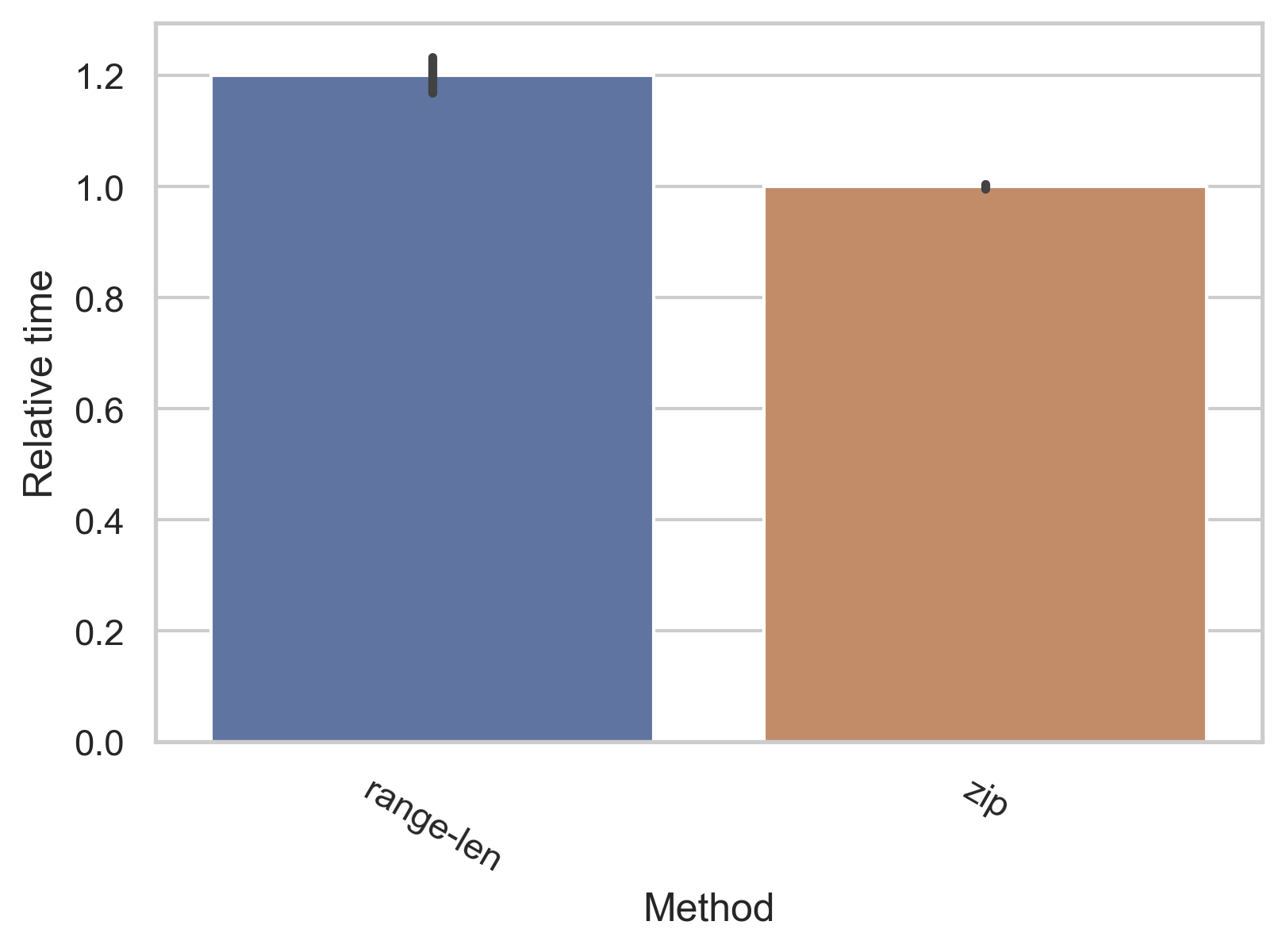
각각 10%, 20% 정도의 속도 차이가 있는데요, 따라서 indexing 한 번마다 대략 10% 정도의 속도 손해가 있다고 보셔도 무방하겠습니다.
One more thing
enumerate에는 많은 사람들이 모르고 있는 추가적인 keyword argument인 start가 있습니다. 듣자마자 예상하셨겠지만, 시작하는 index를 정해줄 수 있는 기능입니다. 그동안 i + 1을 쓰시던 분들은 이걸 들으면 뒤로 넘어가시겠군요.
# Don't:
for i, v in enumerate(a):
foo(i + 1, v)
# Do:
for i, v in enumerate(a, start=1):
foo(i, v)
역시 벤치마크가 빠지면 섭하죠? 이번에도 약간의 속도 차이가 있습니다.
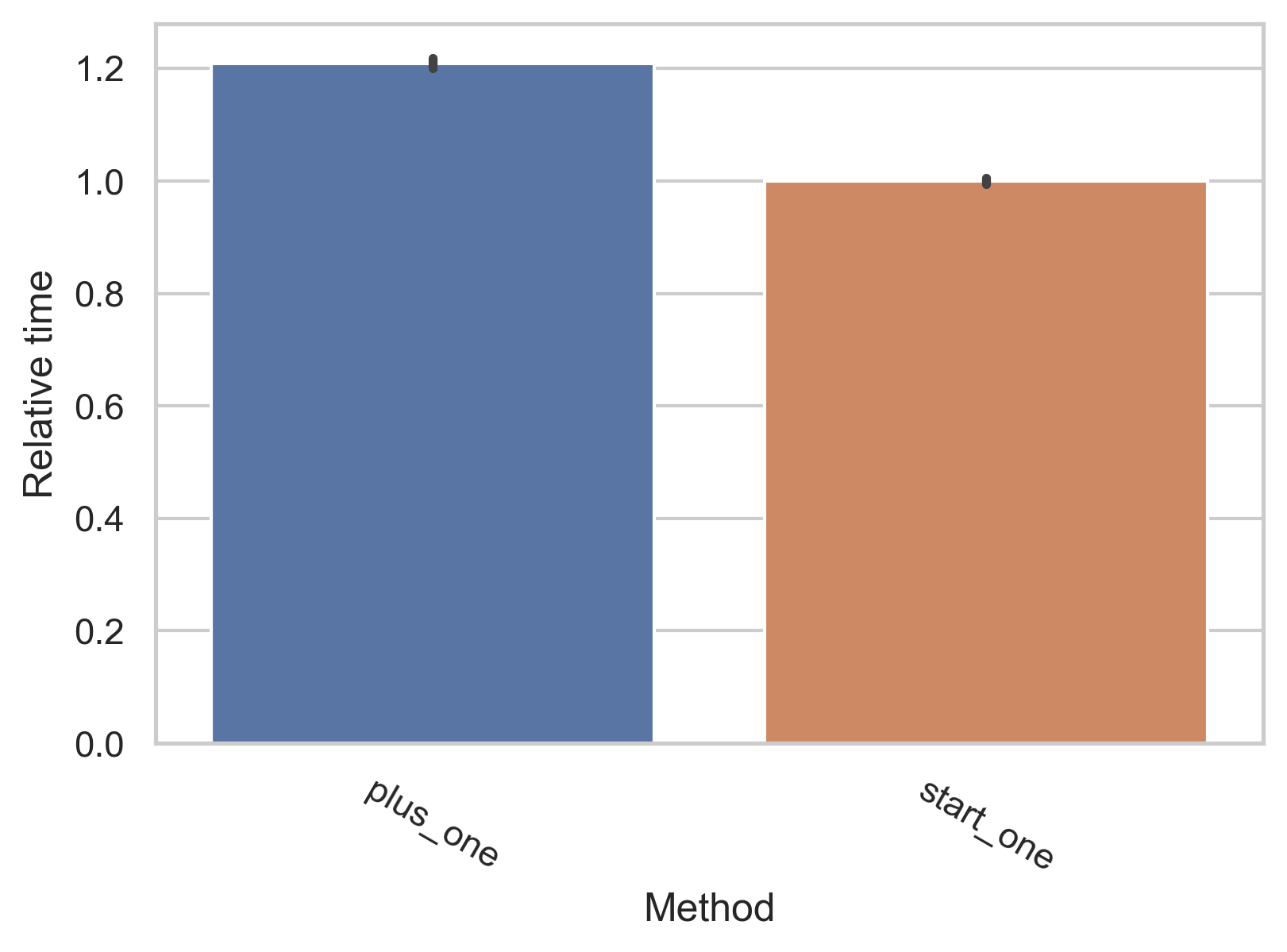
이보다 복잡한 경우에는 zip과 조합하여 더 빠르게 실행할 수는 있지만, 대부분의 경우 코드의 가독성을 크게 낮추고 실수할 여지가 늘어나기 때문에 시도하지 않는 것이 좋습니다.
# Don't:
for i, v in zip(range(0, len(a) * 2, 2), a):
foo(i, v)
# Do:
for i, v in enumerate(a):
foo(i * 2, v)
Boolean evaluators
꽤 유용한 기능인데, 많이들 모르고 계시는 any와 all function에 대한 간략한 소개입니다. 다음 두 for문은 한 줄로 짧게 줄일 수 있습니다.
# For loop
for i in a:
if i % 2:
print("There is an odd number")
break
# any()
if any(i % 2 for i in a):
print("There is an odd number")
# For loop
for i in a:
if not i % 2:
break
else:
print("They are all odd numbers")
# all()
if all(i % 2 for i in a):
print("They are all odd numbers")
간단한 for문은 이렇게 any나 all로 바꾸기만 해도 코드의 가독성이 크게 증가한다는 장점이 있습니다.
Iterating dict
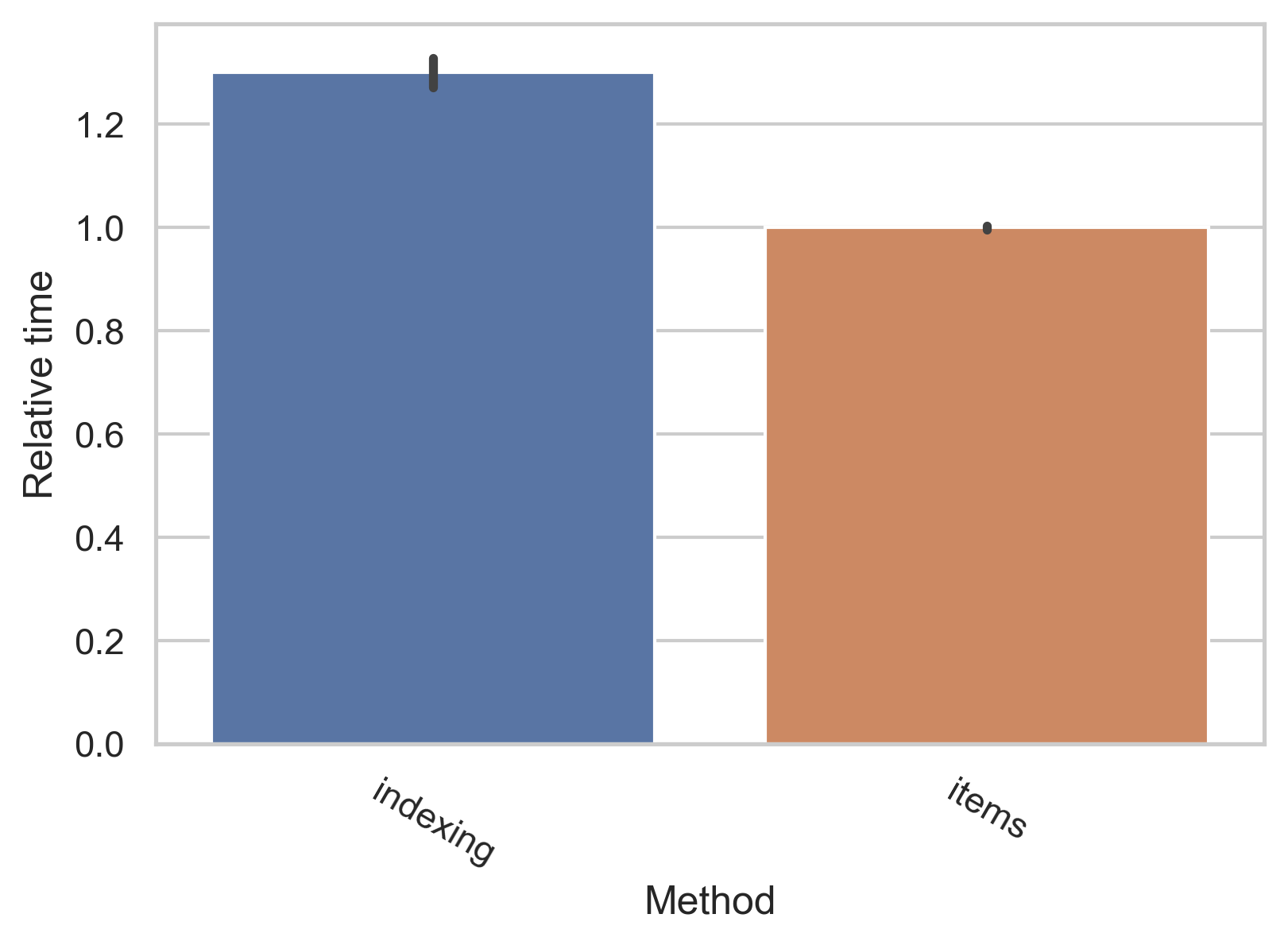
dict 타입은 아주 빠르고 유용하며, Python에서 list와 더불어 자주 사용됩니다. 그러나 dict 타입을 iteration할 때 많은 사람들이 key와 value를 동시에 얻지 않고, 추가적인 indexing 비용을 지불하는 방식으로 사용하는 실수를 저지릅니다.
# Don't:
for k in d:
foo(k, d[k])
# Do:
for k, v in d.items():
foo(k, v)
두 방식의 속도 차이는 대략 20%가량 납니다1.
New str methods
Python 3.92에 추가된 str 타입의 method는 다음과 같습니다.
>>> s = "This is a sample string"
>>> s.removeprefix("This")
' is a sample string'
>>> s.removesuffix("ing")
'This is a sample str'
>>> s.removeprefix("foo")
'This is a sample string'
해당 prefix나 suffix가 존재하지 않으면 원본을 그대로 반환하므로, 문자열 처리에 굉장히 유용하게 사용 가능합니다.
Wrap-up
이번 글에서는 Python의 built-in function과 type에 대해 간단히 살펴보았습니다. 더 많은 정보는 각각 여기와 여기를 참고하시면 됩니다.
다음 글에서는 실제 코딩에서 아주 유용하게 사용되는 파일 및 경로 관련 library에 대해 알아보겠습니다.
-
여기에서 소개하는 결과는 가장 자주 key로 사용되는
str타입을 기준으로 한 결과입니다. Python의dict타입은 hash table로 구현되어 있으므로, 벤치마크 결과는 key의 hashing에 필요한 연산량에 따라 영향을 받습니다. ↩ -
Released on Oct 2021. ↩